Customer data, personal information, and regulated fields like social security numbers, protected health information, and the primary account number (PAN) are copied across systems, logs, cloud analytics, and third parties – turning a single mistake into a reportable data breach and escalating breach costs.
Tokenization is how enterprises neutralize that risk by ensuring lower-value systems never see the original data.
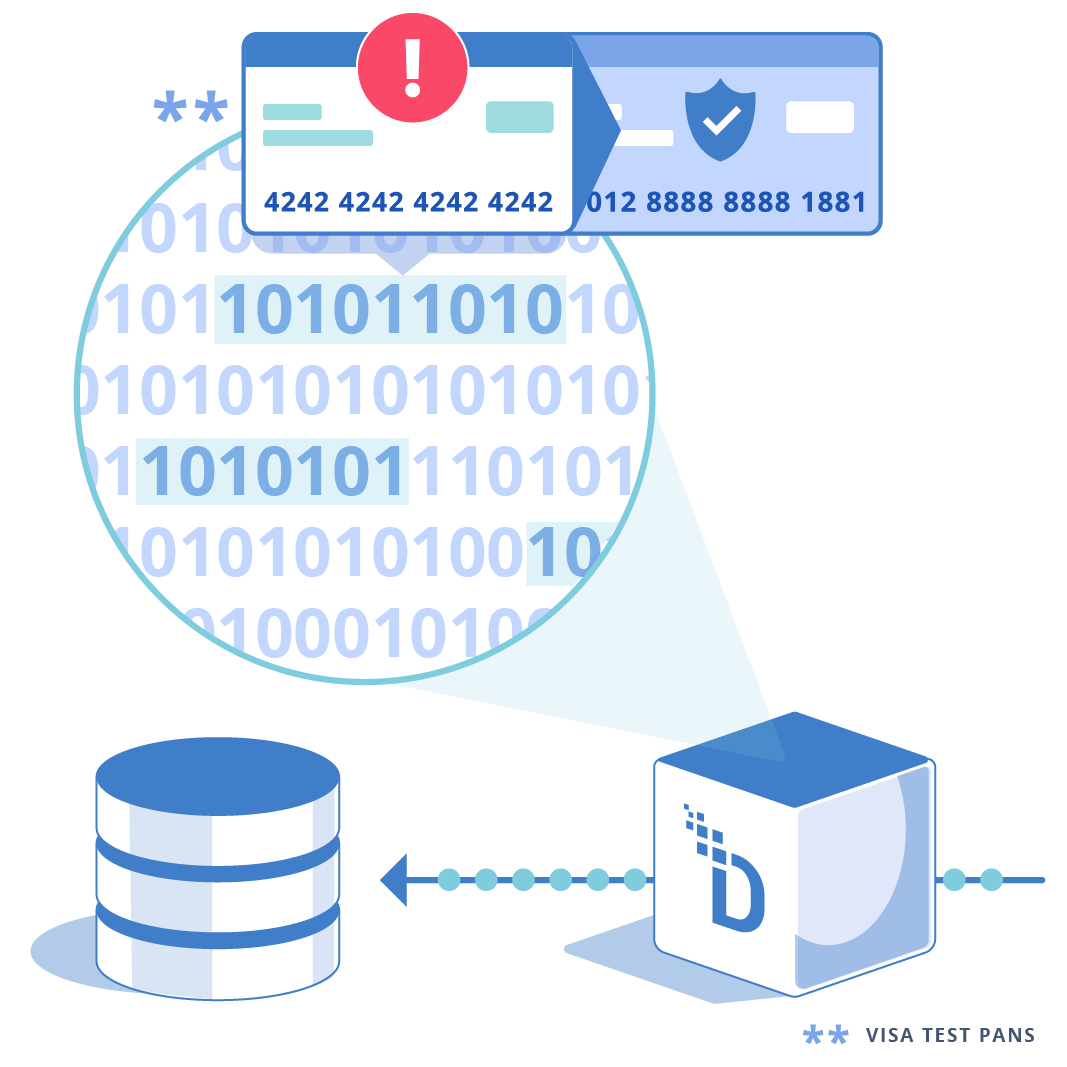
DataStealth delivers data tokenization solutions that replace sensitive data with tokenized data (tokens) before it lands in databases, apps, files, or cloud services.
Because tokens have no exploitable meaning outside the tokenization system, they reduce the blast radius of compromise and trim compliance scope.

More secure data, simpler compliance, and a cost-effective tokenization solution that protects high-volume systems without adding the latency and refactoring tax that kills projects.

4.8/5 rating on G2 and other review platforms for data-centric security and ease of deployment.

Named a top data security platform for giving organizations visibility into shadow IT and high-risk data.

DataStealth is recognized in Forrester’s Data Security Platform Landscape Report and trusted by highly regulated organizations that cannot afford data exposure or downtime.
No Refactoring, No Performance Hit
Tokenization should be simple in theory: replace sensitive fields with valueless tokens. In enterprise reality, tokenization fails for predictable reasons:
DataStealth is built to avoid those traps.
We tokenize at the data layer so you can protect PANs, PII, and PHI across hybrid estates without rewriting apps.
BOOK A DEMO TODAYWe support the token types and controls enterprises demand – format preservation for legacy compatibility, deterministic behavior for analytics, strict access controls for detokenization, and key control models like BYOK/HYOK, security improves without operational drag.
Tokenize primary account numbers (PAN) before storage; downstream systems only process tokens, reducing exposure and simplifying compliance obligations under PCI DSS.
Use deterministic tokenized identifiers so teams can join and analyze data in cloud platforms without exposing personal information or customer identifiers to broader access.
Replace sensitive fields before data is replicated to dev/test environments or shared with vendors. Pair with data masking where appropriate, teams work with realistic values without touching the original data.
Detect regulated data elements (PAN, SSN, PHI) across structured flows and payloads – so protection policies apply consistently.
Built for high-throughput environments so that data tokenization doesn’t become the bottleneck in payments, apps, or data flows.
Log access and policy events so security can review who accessed what and when – supporting audit readiness and incident response.
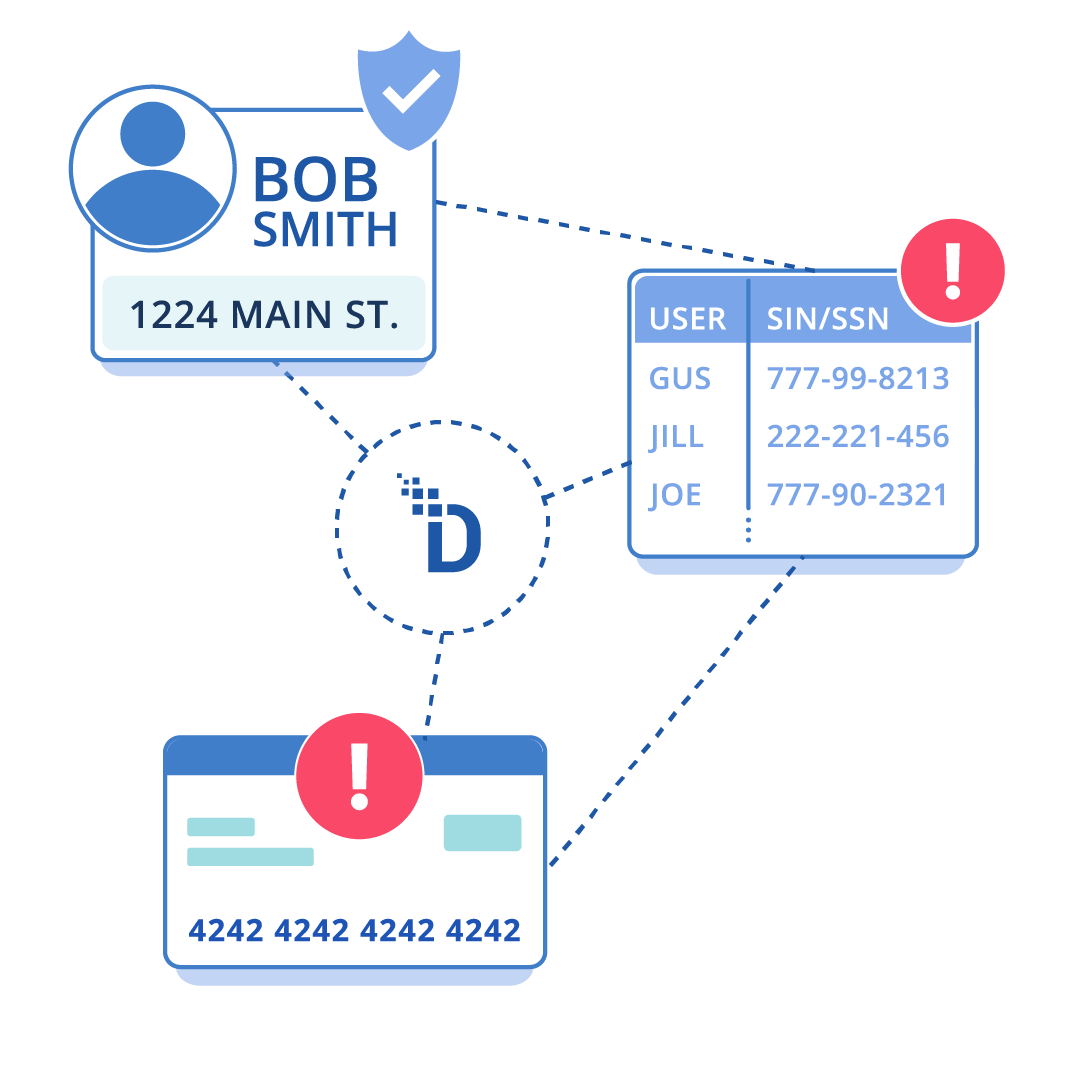
Tokenization replaces sensitive data with non-sensitive tokens that have no exploitable value outside the tokenization system.
Only authorized users/systems can retrieve PAN or other sensitive values from tokens; everything else uses tokenized data. PCI guidance emphasizes restricting PAN retrieval and protecting systems that can retrieve PAN.
Tokens retain the length, character set, and structure of the original value, so legacy schemas, validators, and downstream applications continue to work without disruption or breakage.
Keep tokens compatible with legacy schemas and validators – so you don’t refactor databases just to secure them.
Deterministic tokenization for joins/analytics; randomized for maximum privacy – choose per field and use case.
Keep sovereignty over keys (BYOK/HYOK) and integrate with enterprise key management so security owns the root of trust.
Support regional controls so tokens/keys stay where regulations require.
Tokenize PAN and broader PII/PHI (emails, IDs, SSNs, identifiers) – consolidate controls instead of stacking vendors.