Secure, production-like test data – without spreading sensitive data into Dev, QA, and UAT.


Your test teams need realistic data sets to validate performance, integration, and edge cases. But copying high-quality production data into lower test environments creates “toxic” non-prod sprawl – where sensitive information is easier to access, easier to misconfigure, and harder to govern.
DataStealth’s test data management platform is built to eliminate that trade-off.
We enable you to provision realistic, high-quality test data on demand – and within CI/CD pipelines – while helping you mask sensitive data sources and keep compliance scope under control.

Higher Coverage, fewer blocked releases, zero sensitive exposure

4.8/5 rating on G2 and other review platforms for data-centric security and ease of deployment.

Named a top data security platform for giving organizations visibility into shadow IT and high-risk data.

DataStealth is recognized in Forrester’s Data Security Platform Landscape Report and trusted by highly regulated organizations that cannot afford data exposure or downtime.
Automated Refreshes, Faster Releases, and Zero Sensitive Data Exposure.
Teams use real data because it behaves like production: correct distributions, messy edge cases, and relationships that keep systems working.
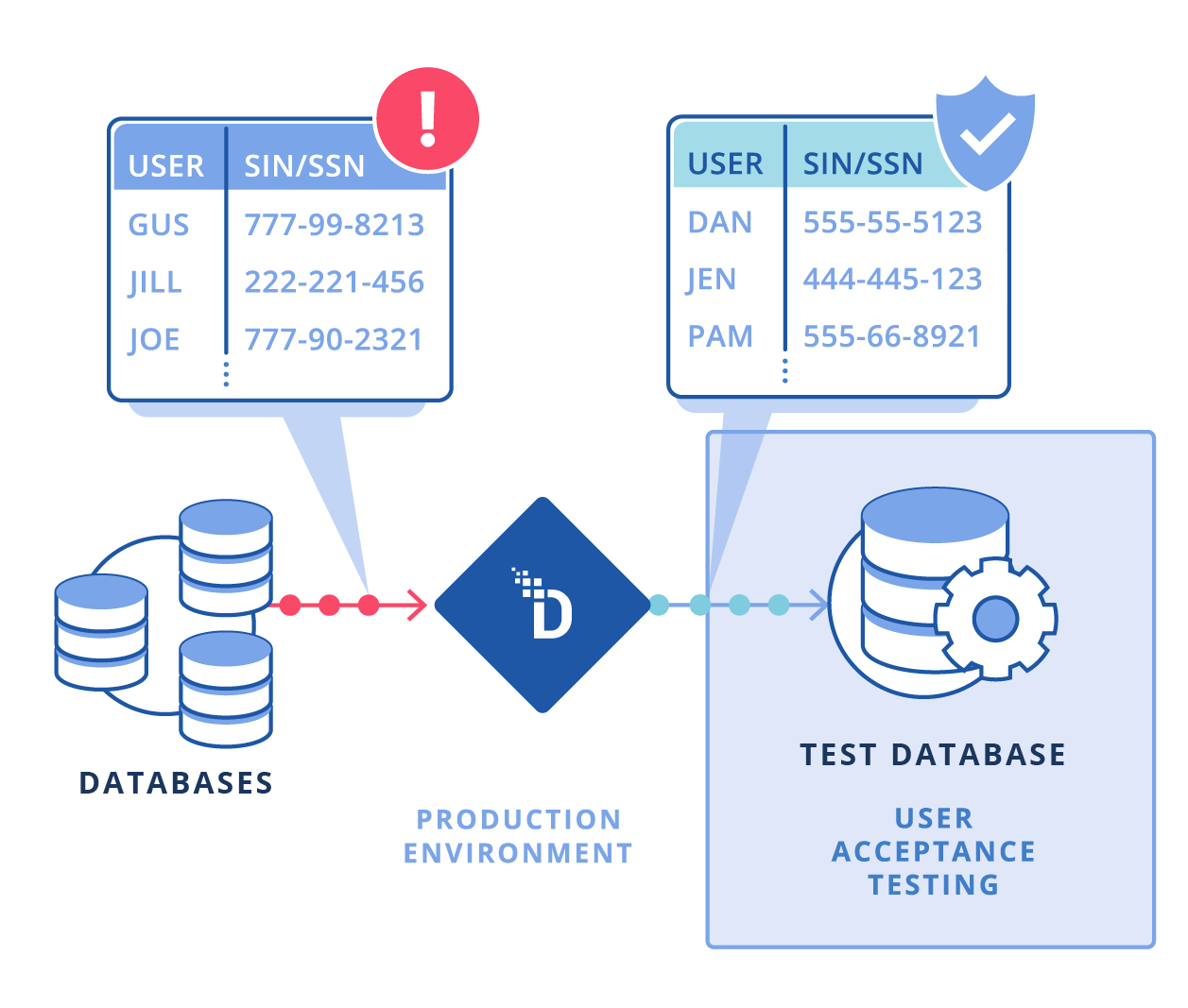
But when real production data is cloned into dev/QA/UAT, it increases the attack surface, makes audits painful, and encourages risky behaviour.
Meanwhile, overly-sanitized or unrealistic datasets lead to false confidence: tests pass, production breaks, and everyone loses a sprint.
Provision a safe dataset as part of your pipeline run so developers and QA aren’t blocked waiting for refreshes. Protect sensitive fields automatically and keep data consistent across builds.
Keep realistic UAT data without dragging compliance scope into non-prod. Reduce exposure while maintaining enough fidelity to validate integrations and performance.
Give external teams what they need to execute test cases and expand test coverage – without exposing real identifiers or regulated fields.
Anonymize production data into meaningful, substituted values – preserving integrity and usability for testing.

Maintains consistent, repeatable replacements across all data sources, so business logic, scripts, and joins continue to work as expected.
Eliminate the need to copy large datasets before generating test data through real-time tokenization.
Generate synthetic data without sacrificing the quality and consistency of your production data.
Generate test data in real time, without duplication, and with virtually no latency – so refresh cycles keep up with delivery velocity.
Host test data on-prem, in the cloud, or within ingestion pipelines for big data and analytics – wherever your teams test and validate outcomes.

Create variable-sized datasets using lookup and row-level selection while preserving referential integrity – so your manageable test datasets stay realistic and usable across related tables.

Integrate with APIs or execute custom scripts to manipulate data and trigger business processes – so test data provisioning fits automated workflows, not ticket queues.
Apply multi-table joins and business rules for intelligent replacements – useful when you need correct entities and relationships across multiple systems and data domains.
Extract and recreate database structures without restoring full production databases – reducing footprint, risk, and setup time for new environments.

Policies can be managed as code with approvals, and actions are traceable with audit trails exportable to SIEM – so security can prove controls over access and policy change events.

Integrate with external KMS and HSMs and support BYOK/HYOK and audited access – designed for regulated organizations that demand strong separation of duties and full accountability.



